前端团队的代码质量建设
回忆一下在米哈游上班的两年学会最重要的东西,应该是大公司里前端团队的工作方式
在此之前,从事的项目都是小团队,一般只有一个前端开发(就是我)或者最多两个。代码想怎么写就怎么写。项目体量小所以混乱但高效
但是米哈游里的项目不同,有技术难点,开发团队人数多,上线质量要求高,沟通场景多,开发流程也比较严格。这种情况下,我欠缺的不再是解决问题的能力,而是对工作环境以及项目质量的适应性
团队协作
刚进入项目的时候只有五六个人,后来随着项目被上面重视,开始扩大规模,增加产能。人数最多的时候将近 20 人
随着人数增加出现过很多问题,比如合并代码丢失,大量代码冲突等问题。为了避免这些问题,做出了不少值得我学习的措施
迭代开发之前
正常的流程是: 需求评审 -> 设计评审 -> 前后端技术评审 -> 功能开发 -> 测试用例评审 -> 测试 -> 产品和 UI 验收 -> 发布
这样的流程在开发时基本上时清晰的,但是不可避免会出现开发测试期间需求变更的问题
在需求评审和技术评审的时候,程序员应该尽可能构建完整的开发思路,思考产品设计和现有功能的矛盾点,可行性如何,如果有问题,就告诉产品经理。这样做可以从需求合理性的角度避免开发期间的需求变更
(避免开发期间的需求变化就是减少加班)
编辑器统一
在项目中创建.vscode 文件夹,不要加入.gitignore,可以让团队每个人的编辑器设置保持一致。避免因为一些插件或者选项导致的提交冲突或者代码问题
1 | ./.vscode |
依赖统一
为了保证所有人的开发环境一致,不要把 lock 文件放入.gitignore
如果对代码一致性要求严格,可以在 package.json 里锁定版本
1 | "dependencies": { |
创建.npmrc 文件,统一 npm 源,以及项目里的一些 npm 设置
1 | registry=https://XXX.com |
建立 git 使用规范
分支管理
米哈游的本地化项目里有清晰的分支意义,分支与运行环境相关联:
master:同步预发布环境代码,添加 tag 时可以选择发布生产环境
pre: 预发布环境(生产环境,测试数据)
dev: 测试环境(测试环境,测试数据)
feat: 测试环境
需求确定后,从 dev 分支拉出自己的开发分支(feat)进行开发,开发完成后合入 dev 分支进入测试阶段
Merge Request
在此我只知道 pull request,拉去请求。团队内使用 gitlab,每当完成自己的 feat 分支开发时,会在 gitlab 上发起一个 merge request,代码 diff 通过 code review 之后才会合入 dev 分支
如果是需求开发,commit 的意义不需要保留,那么可以在 mr 的时候将多个 commit 压缩成一个
测试完成,进入预发环境的时候,会从 dev 提交一个 merge request 到 pre 分支,通过 diff 可以看到一次迭代修改的所有代码。根据 diff 进行 code review
git rebase
为保证提交历史的干净整洁,团队没有采用传统的 merge 合并代码,而是 rebase。
既然使用了 rebase,有时候就需要对 commit 进行 drop 或者 squash 等一系列的操作。除了手动在命令行中使用git rebase -i 之外。更推荐使用 git 图形工具来做,比如fork
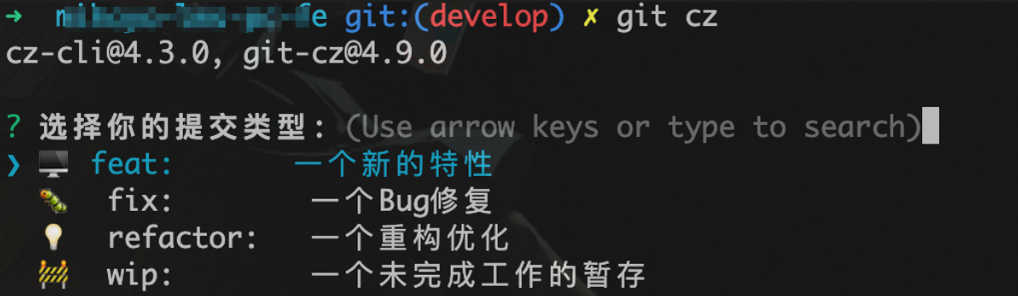
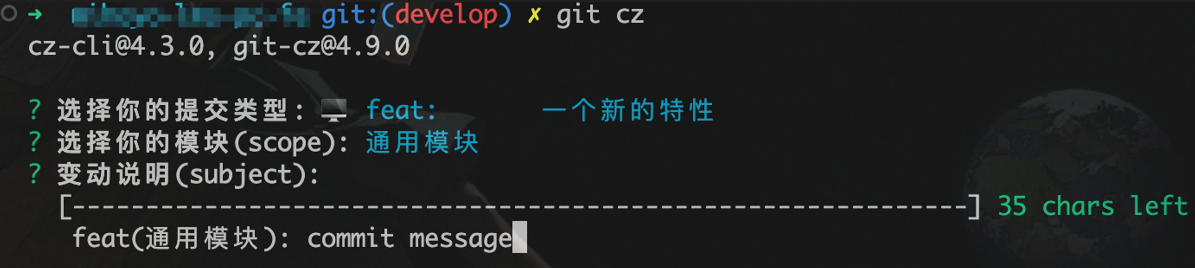
commitizen 和 git-cz
使用 commitizen 和 git-cz 来替代 git commit -m 可以约束项目参与者的提交信息
代码质量
除了团队协作中的约定,采用一些手段来确保项目成员所编写的代码质量也十分重要
TypeScript
如果项目比较大,业务逻辑复杂,引入 TS 是非常必要的。
编码效率方面,ts 会给出很好用的编辑器辅助
更重要的是代码的健壮性,给 JavaScript 添加类型约束之后,避免了很多 bug 的出现。而且在添加类型的过程中,也会修复许多的隐藏 bug
ESLint
ESLint 可以保证项目中的语言语法规范。
可以通过 .eslintrc 文件来约束语法使用,可以用.eslintignore 忽略某些文件的 ESLint 检查
项目里我们使用 ESLint + Prettier 格式化代码,ESLint 和 Prettier 可能会产生规则冲突,可以使用 eslint-config-prettier 这个工具辅助进行代码格式化
husky & lint-staged
除了写代码的时候进行格式化,在提交代码的时候也需要把暂存区的代码都进行一次 lint 和类型检查
husky用来在运行 git 命令的时候运行一些函数或者其他命令。比如 pre-commit 钩子
lint-staged用来过滤出暂存区的更改
所以 ts + eslint + husky + lint-staged 可以在 pre-commit 的时候 对暂存区的代码进行 lint。从而保证了每次 commit 的代码都是符合 ESLint 规则且没有 TS 问题的
流水线检查
除了提交的时候检查代码规范,还会在流水线运行的时候再做一次检查
流水线检查是为了避免代码合并后出现的问题
模块划分
清晰的模块划分可以提高代码的可维护性
我对模块的理解是:负责特定功能的独立的代码集合
模块之间可以有引用关系,但是引用关系必须是单向的。
项目中划分模块可以分为下面几种
- 通用模块:一些通用逻辑,比如登录,用户信息,全局状态。这些应该被独立为模块
- 工具模块:工具函数,网络请求的封装,日志等
- 业务模块:业务逻辑的分割
单元测试
单元测试是通过一些工具去验证程序的最小可测试部分是否按照期望结果运行
“单元”可能是一个函数,一个类,或者一个模块
单元测试的过程是:对单元指定运行环境,入参,期望结果。程序在指定环境中接收入参返回的结果是否与期望结果一致
关于什么是单元测试,单元测试的意义,以前的同事给过一篇知乎的答案来解释
在公司项目里,我们曾经使用 vitest 来做单元测试
1 | "@vitest/coverage-istanbul": "^0.33.0", |
1 | // sum.js |
1 | // sum.spec.js |
UI 自动化测试
相比单元测试,UI 自动化更偏向于视图的实际表现
UI 自动化就好像模拟人类在网页上的操作行为,测试用例基本都可以转化为 UI 自动化用例来执行。
UI 自动化的行为逻辑实际上是:登录(如果需要) -> 找到元素 -> 触发事件 -> 事件触发结果是否符合预期
可以使用 playwrite 库进行,以下是一个测试登录页面的例子
1 | const AccountTest = { |
封装测试工具
1 | // e2e/utils.ts |
自动化用例编写成本比较高,而且会因为迭代造成较大的变动
安全性检查
公司安全组会对项目进行安全性检查,寻找潜在的安全漏洞
主要包括 SQL 注入、XSS 攻击等
除此之外,npm 包也会要求使用公司的自建镜像。从而防止供应链攻击
运行监控
除了团队协作和代码规范,在代码发布到生产环境之后会采取一些措施来监控代码运行稳定性
埋点
通过埋点收集用户行为,埋点可以让产品经理分析用户的使用习惯。也可以给开发者复现生产环境错误提供线索
这是一个简单的埋点上报接口类型
1 | interface Action { |
错误监控
通过 Sentry 等工具对生产环境进行错误监控,可以收集到生产环境下程序运行出现的错误
许多报错往往看似不影响程序正常执行,但是在某些边界场景中,就有可能造成生产事故
收集生产环境的错误,及时修复。就如同在清理项目里的定时炸弹
 微信
微信- 支付宝


